One of the algorithms that I learned when I worked on Cobol and C was how to merge two datasets. At that time programmers called it the hi-lo algorithm. I learned it because I had to use it in a lot of different programs. The basic premise of this algorithm is to join two or more datasets based on some pre-defined criteria.
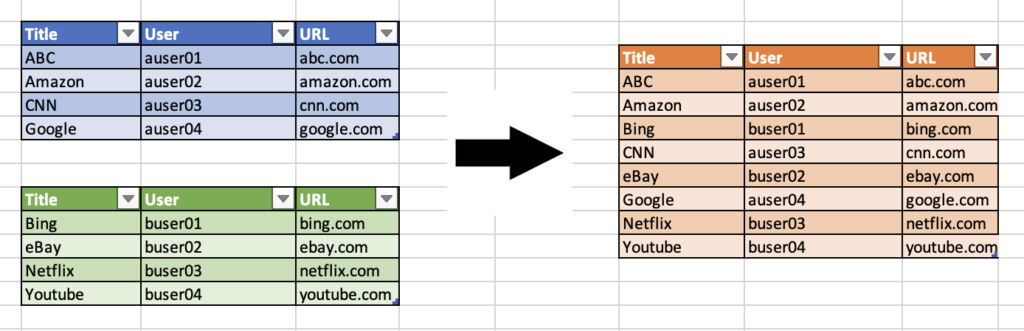
I put a sample above where two datasets are merged to create a new dataset. It is a very efficient looping as the entire thing runs on O(n) complexity.
Algorithm Basics
I am adding below the steps for this algorithm,
- Sort both dataset on the sort key
- Open both lists, and iterate one item at a time using two counters
- If the items match,
- Add the newer message to merge list
- Increment both counters to read next record from list
- If item only exists in left list,
- Add this record to merge list
- Increment the counter for the left list only
- If items only exists in right list,
- Add this record to merge list
- Increment the counter for the right list only
- Keep on repeating till we exhaust both lists
I will present next a real use case where I had to use this algorithm recently.
Example Implementation
I use a offline password store extensively. Since it is offline, and I work out of different machines, there is always a tendency of this database going out of sync between the different machines. I plan to use a NAS drive to keep the DB, but that also does not solve the problem when I am out of my home. All of these just because I do not want my passwords to be stored online :).
Anyway, I digress. After I came back from vacation one of these password databases was all out of sync from my master database. So, I had to merge the databases – and the first thing I remember was the way we used to merge using Cobol.
The structure of the data looks as follows,
title: Some name for the entry user: Username for the site password: Password url: URL for the site groups: Add to the group created: When was this created? modified: When was this modified? notes: Notes tags: Tags
What we are doing in this is to get two copies of the data files and merge them based on the algorithm defined above.
Algorithm Implementation
We will define couple of utility functions before we start the main implementation. The first one is for loading a file into a specific structure.
@staticmethod
def load_file(flname):
fl_array = []
with open(flname) as csvfile:
flreader = csv.reader(csvfile, delimiter=',', quotechar='"')
for flrow in flreader:
rec = {
'title': flrow[0],
'user': flrow[1],
'password': flrow[2],
'url': flrow[3],
'groups': flrow[4],
'created': flrow[5],
'modified': flrow[6],
'notes': flrow[7].replace('"', "'"),
'tags': flrow[8]
}
fl_array.append(rec)
fl_array = sorted(fl_array, key=lambda ele: (ele['groups'], ele['title']))
return fl_arrayIn the code above, we load the file into appropriate structure, sort it by groups (primary) and title (secondary). It is not required to sort in that order, any sort order should be okay. We have to use the appropriate sort order based on business requirement.
The second function we need is to compare dates.
@staticmethod def compare_dates(d1, d2): dt1 = datetime.datetime.strptime(d1, '%m/%d/%Y %I:%M %p') dt2 = datetime.datetime.strptime(d2, '%m/%d/%Y %I:%M %p') return dt1 > dt2
Now we start the real algorithms. First step is to load both the files and count the number of records in each one of them.
f1arr = CompareFiles.load_file(f1name) f2arr = CompareFiles.load_file(f2name) f1len = len(f1arr) f2len = len(f2arr)
Now the following has to be done while we keep on looping the files,
# Read record and extract key (f1/ f2 are counters) rec1 = f1arr[f1] rec2 = f2arr[f2] key1 = rec1['groups'] + '-' + rec1['title'] key2 = rec2['groups'] + '-' + rec2['title']
If both the records are same (key match), then we check the newer record and store. Since it was a match, we will also increment both counters.
if CompareFiles.compare_dates(rec1['modified'], rec2['modified']):
# Record 1 is newer
final_list.append(rec1)
else:
final_list.append(rec2)
# Increment both counters
f1 += 1
f2 += 1Next option is record does not exist in one of the files. In this case we append the record to final list and increment only the counter for that file.
elif key1 > key2:
# Record 2 does not exist in File 1
final_list.append(rec2)
f2 += 1
else:
# Record 1 does not exist in File 1
final_list.append(rec1)
f1 += 1Finally, we have the exit criteria to break the loop. This is very simple. We just check if both the counters exceeded the total number of records in file, we break.
if f1 >= f1len and f2 >= f2len:
break_loop = TrueFinally we will return the full array that we were storing.
Conclusion
So this is the full implementation for hi-lo algorithm. It is one of the efficient algorithms for merging two different datasets. Hope you find this useful somewhere. Ciao for now.