| Prev: – | Current: Introduction | Next: Installation |
I will start this blog with a caveat. If you are looking for advanced database concept, this is not the correct blog for you. This is intended to just glide through the basics. This will probably need just three blog posts to complete. I have put an index on top to navigate.

So, I have been trying to explain basic database concepts to a non-developer friend of mine. In this case the need is to understand what database is and how database selection works. We will only cover relational databases at this point. We may pick up non relational databases at a later point in time.
What is a Database?
Briefly, database is just a data storage. It allows you to store structured or unstructured data. Think about a scenario where you want to maintain a list of all the products you are selling in your marketplace. What is a good place to store this data? One option would be to just store it in a flat file. But now to search this file you will have to go in a sequential manner. There are ways to speed up search, but that involves additional coding from developer. A database in turn allows you to solve this problem by providing a way of easy storing and retrieving of data. From a developer’s perspective, it means that we do not have to code for a lot of ancillary tasks associated with data storage.
Apart from storing and retrieving data, a database can also be used for data analytics and reporting. Since analytics and reporting is a key need for businesses, a database serves to cater to that as well.
About Structured Query Language (SQL)
We will briefly talk about Structured Query Language (SQL) before we go further. This is because we will use this term in the next section. SQL is a programming language that is used extensively by Relational databases defined below. We use SQL to query, create, update and delete database object. Based on the type of function we do, we can also sub-divide SQLs into various groups.
- DDL (Data Definition Language) defines database object creation, alterations and deletions. We can say it describes the metadata for the database. DDL scripts create database schemas and various data models. More on this later.
- DML (Data Manipulation Language) is used for inserting, updating or deleting data from a database. We will discuss DML in more details in future blog posts.
- DQL (Data Query Language) is part of DML and only deals with querying database objects.
Types of Databases
We can segregate databases into various groups based on different parameters. However, for most cases, we will just talk about the following two database types. Remember, this list is not exhaustive but indicates the most used ones.
- Relational Databases (RDBMS) – These kind of databases store data in tables and maintain relationship between multiple tables using shared keys. Example of these databases include Oracle, MySQL, SQL Server, Aurora etc.
- NoSQL databases – These databases store and manage unstructured data. They will use different data structure to maintain data instead of tables. Example of these databases include MongoDB, CouchDB, Neo4J, Cassandra etc.
Database concepts
Schema
A database schema aggregates the metadata for tables, relationships and constraints into logical groupings. Normally a separate schema is created for each database user created.
Entity
This resolves to a table in the database. A table is a logical storage that keeps data organized in columns and rows. Row of a table is also called a record. We used DDL to define columns, however we use DML to insert/ update/ delete records,
Keys
A key is a set of one or more database columns that will uniquely identify a record. For example, for a Employee master table, we can define Employee ID as a key. We have the following types of keys in database:
- Single Primary Key: This is a single column that will uniquely identify the record.
- Composite Primary Key: This is a set of columns (more than one) that will uniquely identify the record.
- Foreign Key: This is a link from one table to the primary key of a different table. It helps in maintaining relationship between the two tables.
- Surrogate Key: Sometime there is no unique key for a table. In this case a dummy key is created to identify the record. We call this surrogate key.
Index
Index is a helper key managed by the database. It helps in executing queries faster. Developers create indexes on fields frequently used fields in queries. Primary key will always create an index behind the scene.
Commit/ Rollback
Commit means saving a record to the database. On the other hand, rollback means discarding the last executed DML statements after previous commit. Commits and Rollbacks happen in a session.
View
A view filters and displays data from one or more tables. Developers use views for convenience. Database fetches data for a view dynamically when run. A materialized view on the other hand also stores filtered data.
Stored Procedures (SP)
Stored procedures keep a set of SQL statements. Any user with access can execute them when needed. This helps in enhancing productivity.
More on SQL Constraints
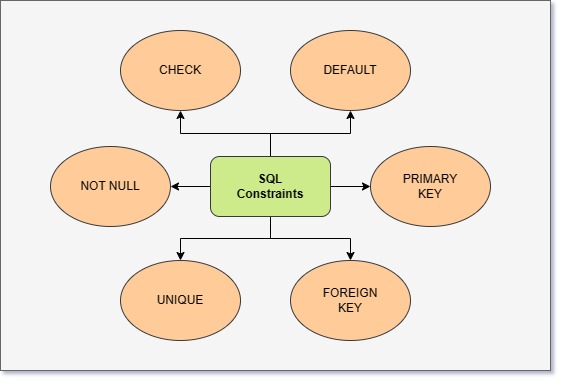
Simple put, SQL constraints are used to define additional rules around a table during creation. We have provided all SQL constraints available in the diagram above.
- Primary Key Constraints: Used to uniquely identify a record
- Foreign Key Constraint: Used to indicate a link to the primary key of a different table
- Unique Constraint: Defines that the column should have unique values
- Not Null Constraint: Enforces that column always has a value
- Check Constraint: Along with a check definition, enforces the check condition that is defined
- Default Constraint: Defines the default value for a column
Let’s talk Transaction
A database transaction is a unit of work. Database either completes it as a whole or rolls back the entire thing. When we talk about transactions, we also come up with a few terms. One of them is data consistency models. Following are the two primary models:
For Relational Database we define the characteristics as ACID.
- Atomicity (A): This is what transaction is all about. If part of the transaction fails, everything has to be rolled back.
- Consistency (C): All database transactions should abide by the database defined rules.
- Isolation (I): Each transaction in the database should be independent of any other transactions and do not compete against each other.
- Durability (D): Even on database failures, transactions has to be stored durably. Most databases manage this part by using something called transaction logs.
So, if relational has ACID, no prize for guessing what non-relational database characteristic will be. Of course, it is BASE.
- Basic Availability (BA): This means that the database is mostly available for use. We may replicate the database across multiple servers to provide redundancy and higher availability.
- Soft State (S): Unlike ACID consistency, this says that data does not have to consistent at all time. A developer is responsible for ensuring consistency.
- Eventual Consistency (E): Of course, at some point of time the database will reach a consistent state.
An example before we wrap
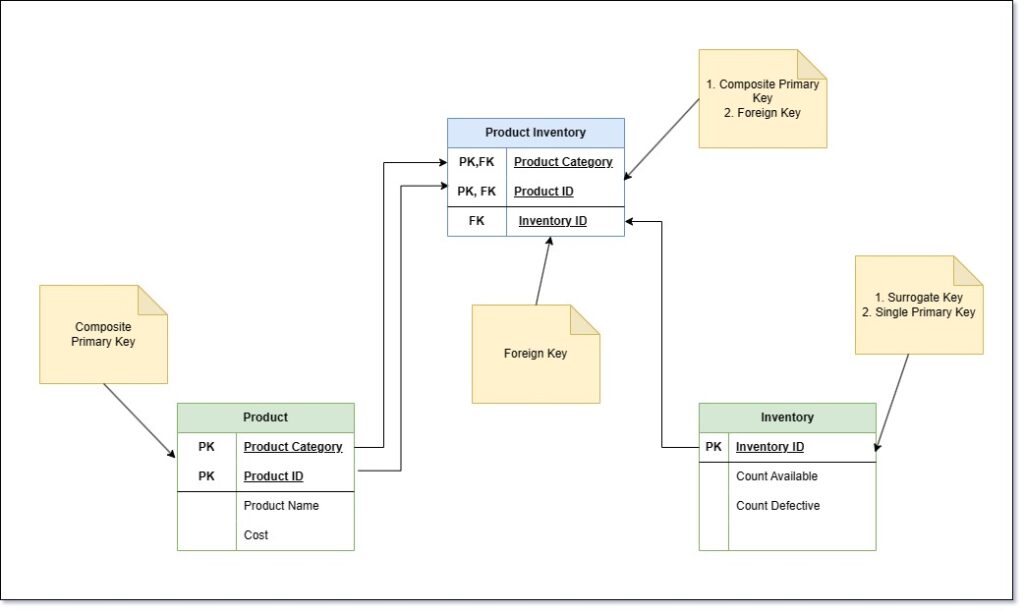
We will provide an example before we wrap up this section. Consider the diagram above. We have defined three different tables here viz. Product, Inventory and Product Inventory. This is a hypothetical definition and it does not define a real world situation. For product, we have defined a composite primary key consisting of Product Category and Product ID. So, if refrigerator is a product, we can have the Product Category as Appliance and Product ID as A0001. Since we have a composite primary key, we are now open to have Product ID A0001 in a different category as well.
Now let’s consider the second table, Inventory. We do not have a logical primary key for this, so we define an auto generated surrogate key as a primary key.
Now we take the third table Product Inventory. This is a map between the other two table. If you notice, it only contains the primary keys from the two other tables. This is what a foreign key relation looks like.
Conclusion
I believe that is enough information for a non-developer. In the next section, we will portably install a MySQL database and also install some sample data to work with. Ciao for now!