
Hello readers, with a lot of thing going on different fronts, I do not have too much time to spend on tasks apart from my regular office stuff. But since I am committed to at least a blog a month, I thought it worthwhile to at least put something small for this month.
Here you will get a taste of Python using Objective-C wrapper to speak to you.
Task at Hand
Like I said, this month will be a very simple project. What we intend to do is to create a program that will read through Gutenberg ebooks. Sometimes, your lethargy kicks in and you do not want to read through books. At that time, it is easier to just have someone read the book to you. If you have a MacBook, you already have a lot of voices built in. There are some crazy voices, we will ignore those, but we will still get a lot of pretty nice voices to play with.
For this project, we will use a wrapper on Objective-C. We will use pyobjc. Let’s first create a virtual environment and add this dependency.
% python --version Python 3.12.6 % python -m venv _venv % . ./_env/bin/activate (_env) % pip install pyobjc
Now that we have an environment with the wrapper installed, we are good to go.
Audio Synthesizer APIs
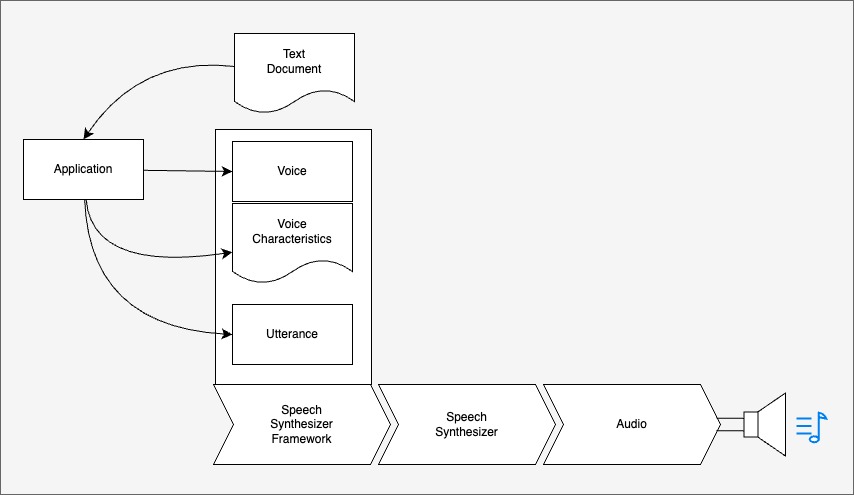
We will first discuss what MacOS provides first. OS X provides an advanced speech synthesizer and quite a lot of voices. OS X provides a Speech Synthesizer framework where you can feed text as utterances, select a voice and have speech synthesizer create audio signal to feed the output device. The synthesizer present will take the words, using specific phonetic rules creates phoneme that can then be used by downstream systems to play on audio devices.
Sound has quite a few characteristics that can also be setup from application. Speech Rate will define how fast or slow the voice plays. Pitch is used to indicate the voice middle tone. That is a 10,000 feet overview of audio API. For more details, Apple has a documentation that can be accessed here on Apple site.
Start building
Let’s start writing the code. As discussed earlier, we are trying to build a Gutenberg reader. Ideally, we could have used requests library to read from the site, but since we will only make one call, I will not add one more dependency, but use in-built urllib for the web call. Given below is the beginning of the project. I will add line numbers, so that it is easier to refer to an individual line and document.
import time
import signal
import sys
import random
import urllib.request as ur
from AppKit import AVSpeechSynthesisVoice, AVSpeechSynthesizer, AVSpeechUtterance
class AvSpeaker:
"""
Quick project for blogging. This is used to read a text ebook from Project Gutenberg.
It can help you in listening to a ebook which you do not want to read.
Uses pyobjc, install using % pip install pyobjc
"""
def __init__(self):
"""
The constructor initializes the class with some constants for voice gender,
and creates an instance of the AVSpeechSynthesizer class.
"""
self.VOICE_MALE = 1
self.VOICE_FEMALE = 2
self.VOICE_UNSPECIFIED = 0
self.synthesizer = AVSpeechSynthesizer.alloc().init()
self.male_voice = ""
self.female_voice = ""
self.random_voice = ""
self.voice_dict = {}
signal.signal(signal.SIGINT, self.signal_handler)
def signal_handler(self, sig, frame):
"""
This method is a signal handler that is called when the program receives a
SIGINT (Ctrl+C) signal. It deallocates the synthesizer object and exits the
program.
"""
print('Got Interrupt, Bye!')
self.synthesizer.dealloc()
sys.exit(0)Some things to note in here. First of course are the imports. From AppKit (which is the wrapper class for Objective C), we will be importing AVSpeechSynthesizer (main voice synthesizer class), AVSpeechSynthesisVoice (voices) and AVSpeechUtterance (utterance). Since we know we will interrupt a lot of these books it is better to handle Interrupt signal. Method signal_handler is used to handle it. Line #29 we are setting this signal handler to handle interrupts.
Rest of the methods are just initializations of variables that we use throughout the program.
Listing all Voices
def get_all_voices(self):
"""
This method retrieves all the available speech synthesis voices from the system,
filters them to only include English voices, and prints their names, genders,
and languages. It also stores the voices in a dictionary self.voice_dict for
later use.
"""
voices = AVSpeechSynthesisVoice.speechVoices()
print("{0:10s} | {1:7s} | {2:8s}".format("Name", "Gender", "Language"))
print("--------------------------------")
for voice in voices:
if (voice.language().startswith("en")
and (voice.gender() == self.VOICE_MALE or voice.gender() == self.VOICE_FEMALE)):
gender = "MALE" if voice.gender() == self.VOICE_MALE else "FEMALE"
print("{0:10s} {1:8s} {2:6s}".format(voice.name(), gender, voice.language()))
self.voice_dict[voice.name()] = voice
print("--------------------------------")
def get_voice_for_name(self, name):
"""
This method retrieves a specific voice from the self.voice_dict based on the
provided name.
"""
return self.voice_dict[name]OS X contains a lot of different voices. Quite a few of them are not suitable for reading ebooks. So, what we are doing here is filtering only for languages starting with en (e.g. en-US, en-GB, en-ES etc.). These ensure that we will always have voices that can read ebooks. Let’s see what voices we get.
Name | Gender | Language
--------------------------------
Gordon MALE en-AU
Karen FEMALE en-AU
Catherine FEMALE en-AU
Martha FEMALE en-GB
Daniel MALE en-GB
Arthur MALE en-GB
Moira FEMALE en-IE
Rishi MALE en-IN
Fred MALE en-US
Nicky FEMALE en-US
Aaron MALE en-US
Samantha FEMALE en-US
Tessa FEMALE en-ZA
--------------------------------On Line #16 we are creating a dictionary that maps each of these names to the full identity of the voices. We will use them later in our program to call individual voices. We have defined a method called get_voice_for_name that returns this value.
def load_speech_voices(self, male_name = "Fred", female_name = "Nicky"):
self.male_voice = self.get_voice_for_name(male_name)
self.female_voice = self.get_voice_for_name(female_name)
self.random_voice = random.choice([self.male_voice, self.female_voice])This method loads default male and female voice, unless they are changed to something else. The idea is when the application inits, it can setup some default voices. We also populate a random voice if no specific voice is selected.
def speak(self, text):
"""
This method takes a voice name and some text, creates an AVSpeechUtterance
object with the text, associates it with the specified voice, and uses the
synthesizer to speak the utterance.
"""
if self.random_voice:
self.utterance = AVSpeechUtterance.alloc().initWithString_(text)
self.utterance.setVoice_(self.random_voice)
self.synthesizer.speakUtterance_(self.utterance)This is the method that really does the “speaking” part of it. We create an utterance, set the voice and finally have the synthesizer send to audio device.
With our framework in place, now it’s just a matter of loading an ebook (text) from project Gutenberg and sending it to this.
def remove_gutenberg_header(self, text):
"""
Removes the Project Gutenberg header from a text file.
"""
# Find the start and end of the header
header_start = text.find('*** START OF THE PROJECT GUTENBERG EBOOK')
header_end = text.find('*** END OF THE PROJECT GUTENBERG EBOOK')
if header_start == -1 or header_end == -1:
return text
# Remove the header
text = text[header_start:header_end]
return text
def read_gutenberg(self, ep):
"""
This method takes a voice name and a URL to a text file (in this case, a book
from Project Gutenberg), downloads the text, and uses the speak() method to
read the text aloud.
"""
fp = ur.urlopen(ep)
bookbytes = fp.read()
book = bookbytes.decode("utf8")
fp.close()
self.speak(self.remove_gutenberg_header(book))
time.sleep(5)
while self.synthesizer.isSpeaking():
pass
self.synthesizer.dealloc()We have defined a method called read_gutenberg that opens the URL and reads the entire ebook text. It then sends it to a method to remove the initial legal headers. Finally this text is sent to the speak method defined earlier.
There are couple of things of interest here. The sleep on Line #28 is required, because I noticed it does take some time to start reading, and if that initial delay is not given, Line #29 returns a False and program exits. That delay ensures that we have started reading.
Finally after reading is done, we deallocate the memory used by the sythesizer and exit.
Conclusion
There are quite a few improvements that I can think of. For very large texts, it is ideal to break in chunks so we do not get an out of memory exception on load. Also, you can create delegates to monitor the speech API. This way you can know what text is being currently read and highlight them.
That completes my short blog for this month. This took up couple of things. We have used a wrapper library to invoke OS X methods directly, and then used APIs to speak text. Hope it helps someone. Ciao for now!