We have already seen the journey to how transformers came into being from Markov Chains.The next part of the mystery is LLMs which is the brain of AI Agents and the reason Agentic AI exists today. This blog will explore this transformative journey, detailing the progression from LLMs to the current state of Agentic AI models. On the way we will also learn how to build simple agents. Grab your coffee and let’s begin.

LLMs
LLMs or Large Language Models are the most basic models that can accept a human language prompt and generate a response based on the huge text data it has been trained on. Behind the scenes, LLMs use transformer architecture that we have already discussed before. However, they are always limited to what they are trained on. So, if a model is trained only on literature, it will not be able to respond to anything that pertains to science or research. This also means if training corpus only contained data till 2022, any event that happened since that day will also be not known to the model. Let’s build a very simple application that uses a LLM model.
Before building the application, for our testing, we will install Ollama to locally run all our code. Changing it to use a frontier model just means changing the model. However, while learning, it is sufficient to use a less powerful open source model. I will later address what changes we will have to make to use frontier models (hint: very little).
Install Ollama
Install Ollama based on instructions on their website. After installation let’s install any of the models you prefer. I will use phi4:14b and nomic-embed-text:v1.5 for this blog. PHI-4 is a model from Microsoft that supports chat format text prompts. I will use Nomic Text for RAG (more on that later). I may install other models as needed, but for now these two should be good enough to start.
% ollama pull nomic-embed-text:v1.5 % ollama pull phi4:14b % ollama list nomic-embed-text:v1.5 0a109f422b47 274 MB 2 weeks ago phi4:14b ac896e5b8b34 9.1 GB 2 weeks ago % ollama run phi4:14b >>> how many moons does staurn have? As of my last update in October 2023, Saturn has 83 confirmed moons. These range from small moonlets to large ones like Titan, which is larger than the planet Mercury and has a substantial atmosphere. The count can change as new moons are discovered or reclassified based on additional observations. For the most current information, its always good to check the latest data from space agencies such as NASA or ESA.
This also starts up a service that can serve LLM. We will use the service from our code instead of command line tool.
Now let’s build something that can translate text. Most of the current language models support OpenAI standard API. One exception is Claude, but for now we use OpenAI. To initialize Ollama, we will have to send the service endpoint to it.
load_dotenv()
self.model_alias = "phi4:14b"
self.temperature = 0.3
self.endpoint = "http://localhost:11434/v1"
self.llm = openai.OpenAI(
base_url = self.endpoint
)OpenAI chat API needs a specific format for the prompt the needs to be sent. It includes a user prompt and optionally system and assistant prompts. Let’s write the method that calls LLM to do the real translation.
def generate_response(self, language_style: str, user_input: str) -> str:
prompt = [
{
"role": "system",
"content": f"You are a translator that converts modern English text to {language_style}. Response should be only the translated text. Be concise."
},
{
"role": "user",
"content": f"Translate the following: '{user_input}'"
}]
response = self.llm.chat.completions.create(
model=self.model_alias,
temperature=self.temperature,
messages=prompt,
stream=False
)
return response.choices[0].message.contentCalling this method with any conversion types like German, Hindi, Japanese or others like Anglo Saxon, Pig Latin etc. will return equivalent conversion.
Query: I am learning to use large language models
—— To Pig Latin ——
Response from LLM: Arrr, I be learnin’ t’ wield grand ol’ language contraptions!
AI Agents
Before we start learning about agents, let’s first see what agents are. AI Agents are softwares that can autonomously make decisions and can act on behalf of users in completing any predefined task (goal). These agents are backed by LLM Models that we have discussed earlier.
So an agent will perceive the environment using sensors, and will act upon the environment through the use of actuators. They can be simple rule based programs, but in this context we will consider them to use machine learning algorithms. An agent will normally have the following characteristics,
- Autonomy: The ability to operate without human intervention.
- Reactivity: Sensing and responding to changes in the environment.
- Proactiveness: Taking initiative based on predictions about future needs.
- Social Ability: Interacting with other agents or humans.
Types of Agents
There are seven types of agents based on their functionality.
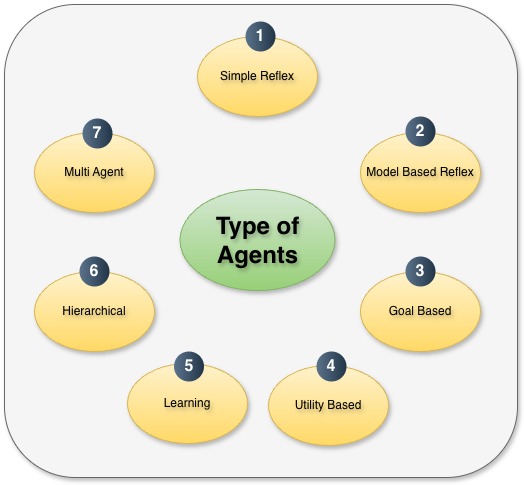
Simple Reflex agents
These agents take action based on current environmental state. They do not have any memory of what action has been taken before. As an example, we can have a switch always change state to ON when ambient light drops below a specific level and switch to OFF when the ambient light is restored back again.
Model based Reflex agents
Model based agents keeps a memory of what has been done before and how it had changed the environment. As a result they can also base their decisions on previous action. An example would be a rudimentary vacuum cleaner. It will need a internal map to know what coordinates are already cleaned.
Goal based agents
These models have the ability to adjust future states based on pre-defined goals. There are no fixed steps to attain the goal. States are assigned dynamically based on defined algorithms. For example if the goal of the model is to advertise a new product, the model will try to advertise out through all available channels.
Utility based agents
This is an extension of goal based agents where the best path to the goal is selected. So, for example if you have to book flight tickets to a specific destination, and want to optimize cost and time, this model will get the flight information for multiple airlines, all flights along with connections for the source and destination selected, optimize cost and time and finally recommend which flight combination to take.
Learning agents
As the name suggests, this kind of model learns using a feedback loop. The model improves performance over time by learning. An example can be recommender systems where the model learns from products bought by a user.
Multi-Agent systems
Modern model rely on more than one models working together or working individually on a pre-defined specialization to achieve the final outcome. These are known as multi agent systems.
Hierarchical agents
Hierarchical agents are also multi-agent systems where tasks are managed hierarchically with models delegating tasks to sub-models. As an example, there may be a model which creates the strategy of how to work on a specific requirement, and based on that delegate each taks to individual agents.
Retrieval Augmented Generation (RAG)
As stated earlier, LLMs suffer from one major drawback, they do not have knowledge of anything after their knowledge cutoff date, neither do they have any information on any personal or corporate data. To get over it, Retrieval Augmented Generation (RAG) was created so that models can retrieve information from external sources. This way the models can still provide accurate data without the need to retrain them again with latest data.
Vector Embeddings in RAG
Before we can dive into RAG, we need to understand vector embedding, that is the backbone for information retrieval. Vector Embeddings are numerical representation of words and capture the semantic meaning of the words. Similar words are grouped closer to each other in vector space.
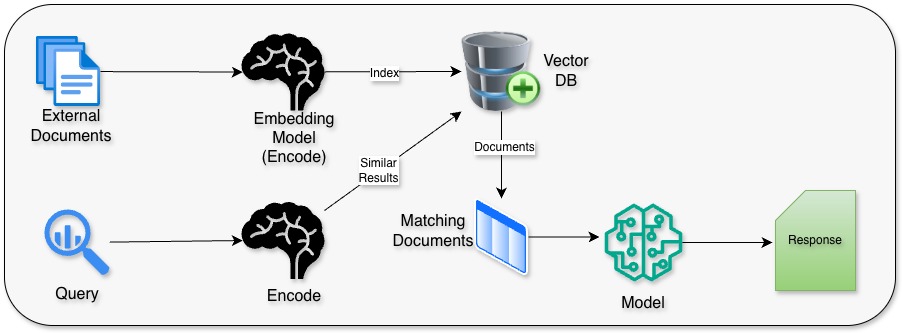
Let’s talk about how this works. The first thing that needs to be done for RAG is to index all external documents. These documents can range from simple texts, markdowns, PDFs etc. The embedding model used will try to extract the semantic meaning of the sentences passed and create appropriate vector representation for them. Words with similar meanings will be grouped together and eventually saved to a vector database.
When we run a query, it’s also converted to it’s vector representation and then searched from the database. Closest matches are returned with probability score. This can be eventually sent to the agent to respond appropriately.
Let’s a build a simple RAG pipeline. We will not use an open source model that is specialized in generating embedding vectors. While installing Ollama, we have already pulled a model called nomic-embed-text. We can use this model to get the vector for each words. To build this model, we will create our own basic text splitter retaining some overlaps so that the context is not lost when we split sentences. This we can use as utility later.
"""
Splits text into chunks of specified size with overlap.
"""
def split_text(self, text: str, chunk_size: int = 500, overlap: int = 50) -> list:
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = ' '.join(words[i:i + chunk_size])
chunks.append(chunk)
return chunks
"""
Reads a file and splits its content into chunks.
"""
def split_file_in_chunks(self, file_path: str, name: str, chunk_size: int = 500, overlap: int = 50) -> dict:
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
return {"name": name, "chunks": self.split_text(text, chunk_size, overlap)}With that in place, let’s start building a RAG agent. We will use ChromaDB (pip install chromadb) to store our vector embeddings. For this example we will use in-memory instance, but in real world, you would want to persist the embeddings. Let’s start by initializing our class.
class BasicRAGAgent:
"""
A basic Retrieval-Augmented Generation (RAG) agent that can embed text chunks
and retrieve similar chunks based on a query using ChromaDB and an OpenAI-compatible
embedding model.
"""
def __init__(self):
load_dotenv()
endpoint = "http://localhost:11434/v1"
self.model_alias = "nomic-embed-text:v1.5"
self.embed_client = AsyncOpenAI(base_url=endpoint)
#persist_dir = "./book_embeds.db"
#self.chroma_client = chromadb.PersistentClient(path=persist_dir)
self.chroma_client = chromadb.EphemeralClient()
self.collection = self.chroma_client.get_or_create_collection(name="book_embeddings")This initiates the model and also creates a Ephemeral (in-memory) DB instance for ChromaDB. We can use this model now to create embeddings and store.
"""
Asynchronously embeds a list of text chunks and stores them in the ChromaDB collection.
"""
async def embed_text(self, lst_file_chunks: str):
for chunk in lst_file_chunks:
total_chunks = len(chunk.get("chunks"))
for idx, text_chunk in enumerate(chunk.get("chunks")):
print(f"Embedding: {chunk.get('name')} - Chunk {idx + 1} of {total_chunks}")
this_chunk = await self.get_embeddings(text_chunk)
self.collection.add(
documents=[text_chunk],
metadatas=[{"source": chunk.get("name")}],
embeddings=this_chunk,
ids=str(chunk.get('name') + "_" + str(idx))
)To extract similar chunks, we can use the following.
"""
Asynchronously retrieves similar text chunks based on a query.
"""
async def retrieve_similar_chunks(self, query: str, n_results: int = 5):
query_embedding = await self.get_embeddings(query)
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=n_results
)
return resultsWe first create the embedding for the query and then we can try to fetch all matching embeddings. To test this, I downloaded three different children books from Project Gutenberg and created the embedding for them. Here is my main class.
if __name__ == "__main__":
# All books are from Project Gutenberg, https://www.gutenberg.org/. Locally saved for convenience.
files_to_chunk = [
{"file_path": "doc/Just_so_Stories.txt", "name": "Just so Stories"},
{"file_path": "doc/The_House_at_Pooh_Corner.txt", "name": "The House at Pooh Corner"},
{"file_path": "doc/Wind_in_the_Willow.txt", "name": "Wind in the Willows"},
]
agent = BasicRAGAgent()
chunks = []
for file in files_to_chunk:
chunked_file = agent.split_file_in_chunks(file["file_path"], file["name"])
chunks.append(chunked_file)
asyncio.run(agent.embed_text(chunks))
query = "What poetry did Pooh come up with about fir-cones?"This correctly returns me chunks where we have the poetry about the fir-cones from The House at Pooh Corner.
For this simplistic example we stopped at retrieval for embedded query, but in real world, RAG will be used with frontier model to enhance knowledge for that model.
Agentic AI
Agentic AI is different from AI Agents in the sense that they exhibit agency like behavior – act independently, make decisions, solve complex problems, translate decisions to actions without too much of human oversight. They resemble human decision making capabilities. Key characteristics for Agentic AI are:
- Intentionality: Systems can align actions with goals or intentions.
- Adaptability: Capable of learning from interactions to improve performance over time.
- Complex Interaction: Engages in sophisticated interaction patterns, potentially involving negotiation and collaboration.
We will not go into too much details on Agentic AI here as we will dedicate an entire blog on creating Agentic AIs and design patterns.
Conclusion
While LLMs, AI agents, and agentic AI all contribute to advancing AI technology, they do so with distinct focuses and capabilities:
- LLMs are specialist models trained in huge corpus of data and excel in NLP tasks.
- AI Agents focus on autonomous action within environments, utilizing a variety of techniques beyond language.
- Agentic AI emphasizes the broader notion of agency, incorporating complex decision-making and interaction patterns akin to human-like behavior.
Understanding the use cases for each of these methodologies helps us in deciding what to use in various application. For example, if we need a basic customer support agent, we can use an AI Agent and marry it with RAG to get a pretty decent working customer support program Hope that helped. Ciao for now!
2 thoughts on “Agents in Agentic AI”
Comments are closed.