
Caching is a widely utilized tool in the toolkit of developers. Its primary purpose is to enhance performance by providing expedited access to frequently accessed data. While caching is predominantly employed for storing master data, there are instances where transactional data may also be transmitted through distributed caches for expedited retrieval.
In this blog post, we will explore various caching modes, strategies for cache management, and an implementation utilizing Infinispan as the caching backend. To simplify the discussion, we will not employ a database layer in this blog post.
Modes of Caching
We will start by listing the different modes how we can cache. Depending on the type of application, we can select what mode we can use.
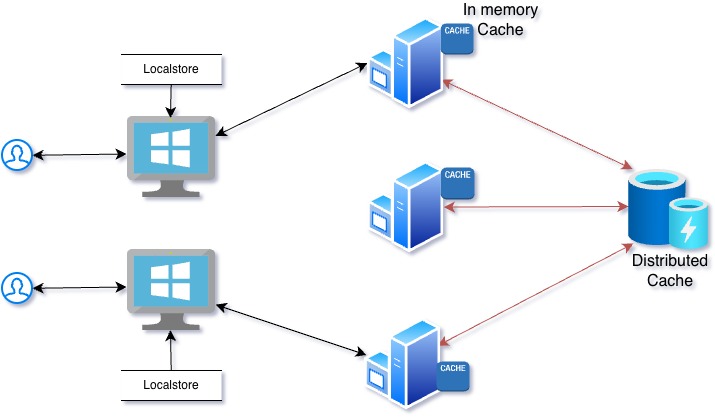
Client Side:
For an application with User Interface, we can cache on the client as well. If it’s a web based application, caching can happen on the browser local storage. For application that is not web based, we can use the local file system to keep some data cached.
Server In memory:
On the server side, the application itself can store some data in-memory for quick access. For example, we may be using some messages that do not change often. We may be using some part names against specified part numbers. They are called master data. This data can be stored in cache as well for frequent access.
Distributed:
Distributed caching is independent of both client-side and server-side caching mechanisms. Client-side caching is specific to individual users, while server-side in-memory caching is effective when there is only one application instance. However, it becomes ineffective when multiple instances of the application are present. To address this, a shared caching mechanism is necessary.
Distributed caching provides an independent solution by operating within its own container and serving multiple instances of the application simultaneously.
Deciphering some terminologies
Before we dive into the next section of the blog, we will decipher some termninologies frequently used with caching.
- Cache Hit: This term means that data was available in cache and returned.
- Cache Miss: Opposite of the previous, this means data was not available and was fetched from database.
- Cache Priming: We may already know of data that will be frequently used by the application. For example, we will always prime system messages. This is because messages are static and normally do not change.
- Cache Lifetime/ Expiration/ TTL: When adding cache data, we always make sure to refresh data from database periodically. The time before it expires is called TTL or Time to Live.
- Cache Eviction: Every cache has a size limit. We cannot keep on adding entries to the cache. At some point, stale cache entries are discarded to make way for new entries. Cold data defined below is the first one to be evicted.
- Cache Consistency: Cache data needs to be consistent with database. Cache consistency refers to making sure that cache is in-sync.
- Hot vs. Cold data: Hot data refers to frequently and recently accessed data. When cache data has to be evicted, these would be the last one to go. On the other hand, cold data refers to cache data that has not been accessed for quite some time.
- Cache Purge: This term refers to clearing the cache. We can setup a API call to initiate purging of specific cache data and refresh them from database.
Eviction Strategies
Caching tools will eventually need to recycle data. There are a few strategies for eviction as well. However, we will talk about the three most used ones.
- Least Recently Used (LRU): In this mode, caching tool saves the latest access time for each item. When purging is necessary, it will always start purging with the oldest data. The assumption in this case is that if the item has not been accessed for sometime, we can discard i
- Least Frequently Used (LFU): In this mode, caching tool keeps an access count for each item. When purging is necessary, it will purge the one with least count.
- Time based:This eviction strategy depends on a TTL attached to each cached item. It will be auto purged when the timer expires. This is useful when we can ascertain how frequently cached items will have to be refreshed.
Strategies for Cache Read/ Write
Now that we know the modes of caching, and have caught up with the terminologies, let’s understand what are the different strategies for cache reads. We can implement caching in a lot of different ways. Each one has it’s advantage and disadvantages. We will select the appropriate caching strategy based on project requirements.
Let’s now go over some of the frequently used patterns.
Read Through
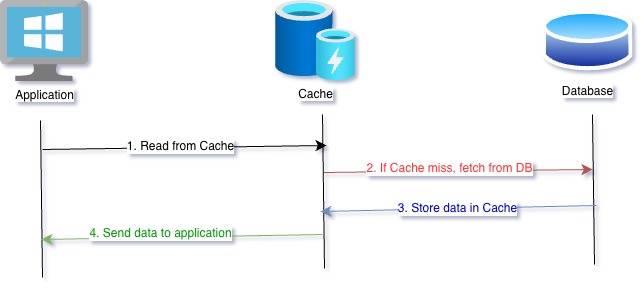
We will start with the first read priority pattern. This as well as the next cache pattern are used when we need a read-heavy use case. Steps are,
- Request data from cache
- If cache hit, send back data and done
- If cache miss, caching system goes to database and gets data
- This data is now cached
- Send back the data to requesting application
The issue with this type of system is that when database is updated from a secondary system, primary system will keep on reading stale data till it expires. One solution to reduce stale data is to reduce the TTL, however, in that case catch hit/ miss ratio will increase causing performance issues.
Read Aside (Cache Aside)
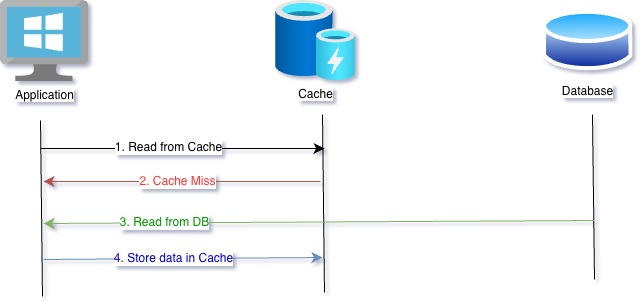
This pattern is very similar to the previous pattern. Let’s see the steps followed in this case,
- Request data from cache
- If cache hit, send back data and done
- If cache miss, send back error to application
- Application gets data from database
- Application further stores this data to cache for future retrieval
In this case, application has to manage the cache retrieval/ refresh from database. It also faces the same challenges as the previous cache strategy.
Write Through
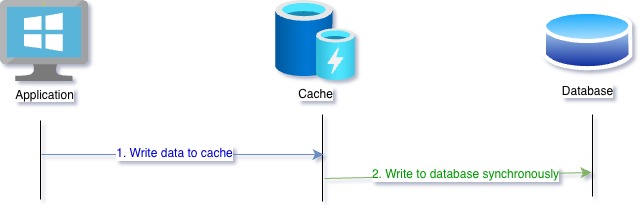
After the two read caching system, we will see some write patterns. The first one we look at is write through. Let’s again follow the steps,
- Application writes to the cache
- Cache system updates the database with changed data
- Application waits while both writes are completed
The problem with this type of caching is that it becomes slow. Since the data is updated synchronously, write process is slow. However, data is always latest in the cache as well as the database.
Write Behind
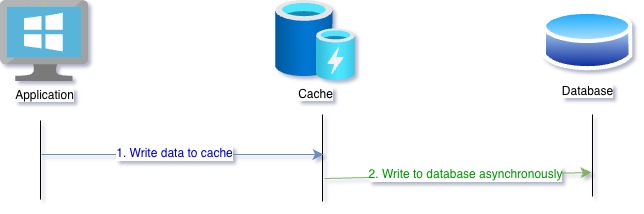
This is similar to Write Through strategy with the difference that database write is delayed. Steps in this case are,
- Application writes to the cache
- Cache stores data and relieves control to application
- Cache system updates the database eventually (asynchronously)
This strategy solves the wait delay we have in previous strategy. However, data in database may be stale while it is not synced. If data is always read from same distributed cache first, this is not a problem for the applications.
Write Around
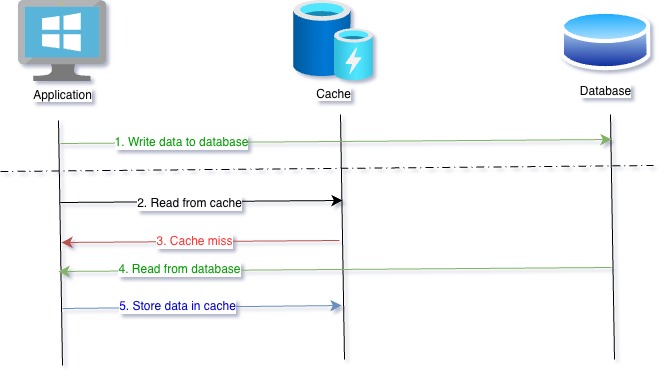
Write around caching pattern is a combination that tries to use best of both world. In this case, data is written to database. When data retrieval is required, process similar to cache aside is followed.
All of these are baseline strategies that work as a starting point. Each system has its unique nuances and a combination of these will be used by them. For example we may want to update product pricing data for an online store every 30 minutes. In this case pricing cache will have a TTL of half hour and since we can use a Read Through cache. On the other hand, employee data for the organization do not change hourly. We can refresh them in cache once every day.
Implementation Examples
Now we will start putting in some examples. We will be using infinispan for the examples. Like a lot of other caching system, infinispan also uses key value pair to store data. For the first part we will not use search features provided by that caching tool. We will manually implement cache search using our own indexing for data we need. Following that we will use ickle which is the SQL like query syntax provided by the tool.
Also, the primary development language used will be Java along with Spring Boot libraries. We will not use any feature of Spring Boot apart for it’s ability to create and expose REST services. This should help make sure that we are only looking at the bare view of caching without mixing with any other specific tools.
So, what are we implementing here? We will implement two different data models just to show how to manage multiple data models. However, we will use one of the models to present our case.
Model 1: WebMessages: This is more of a real world data structure. It will only have two fields, the key for message and the message text.
Model 2: User: This is a concise version of user data structure. We will use User ID, Email, Roles and the Name of the user. We should be able to query this structure using both User ID as well as the Email for the user. Email and User ID are both keys, and both are unique.
Install Infinispan
You can install infinispan server side, in that case you will have to make sure to set the correct server and port. You will also need to make sure that apache or nginx is configured to expose infinispan console. However, for local install for testing, it is just a matter of uncompressing the zipped file.
Go to this website and download the server component. Uncompressed it to the directory of your choice. As long as you have JDK 17+ you will be able to run this server. To run server, use the following command,
$ /infinispan] % ./bin/server.shBefore running the server, you will need to create an admin user using the following command.
$ /infinispan] % ./bin/cli.sh user create admin -p secret -g adminAfter the server starts up, we can access the console at the following endpoint,
http://localhost:11222/consoleFrom the console, we will create a cache named cache-suvcodes. We will use all default settings and will use this newly created cache to experiment with what we need.
We will have to make one more stop before we go to real implementation. The only reason for this is that we are using Infinispan. Even though we will not use tools like Lucene for searching and will be using built ins only, we still have to understand something called protobuf.
What is Protobuf?
Protobuf or Protocol Buffers is a compact, language and platform neutral binary serialization format that was initially developed by Google. We define data structures in .proto files where we specify message, fields and types. We can optionally specify default values as well. Most languages available today support protobuf using external libraries. A sample generated .proto file may look like this.
syntax = "proto2";
package rss;
message Article {
/**
* @Keyword
*/
string title = 1;
string link = 2;
string description = 3;
optional string author = 4;
optional string pubDate = 5; // RFC-822
}Infinispan adds additional features on top of that. For example the @Keyword in comments indicates that this data should be indexed and searchable from Infinispan. We will not cover all nuances of Infinispan here, as it is more about caching strategies.
Key Value caching
Now let’s talk a little bit about Key Value pair caching. In case of key value pair caching, as the name suggests, caching tool stores data in key value pairs. We can have both key as well as value as binary objects. Also, we can have additional values within the value indexed for faster search using them. When talking about Infinispan, it also supports @Text based search. In this case, string data will be processed to extract keywords.
Initializing Spring Boot Application
For this project we will use Maven to initiate. Let’s start with the libraries that we will be including in pom.xml.
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-bom</artifactId>
<version>16.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>${openapi.version}</version>
</dependency>
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-client-hotrod</artifactId>
</dependency>
<dependency>
<groupId>org.infinispan.protostream</groupId>
<artifactId>protostream</artifactId>
</dependency>
<dependency>
<groupId>org.infinispan.protostream</groupId>
<artifactId>protostream-processor</artifactId>
</dependency>
</dependencies>These three sections give information about all the libraries needed. We have added OpenAPI dependency so that we can use swagger for our testing. Infinispan-client is needed for connecting to cache. We will use remote connection as the cache will be served remotely. We have included the protostream libraries to help auto generate .proto files (discussed above) automatically from Java Beans.
With the POM out the way, we will only look at the application.config for values that we have configured.
# Application Name spring.application.name=infinispan-caching-app logging.level.root=INFO # Caching configuration cacheName=cache-suvcodes # Common App Cache Server # infinispan.remote.server-list=127.0.0.1:11222 infinispan.remote.auth-username=admin infinispan.remote.auth-password=secret infinispan.remote.client-intelligence=BASIC infinispan.remote.cache.default.encoding.media-type=application/x-protostream infinispan.remote.marshaller=org.infinispan.commons.marshall.ProtostreamMarshaller infinispan.remote.allow-list.classes=com.suvcodes.demo.cachebean.*
Here we setup the configuration that we will use from Spring to create a custom bean. This would be a great segway to define how our config looks like.
Spring Beans and Configuration
We will start with the spring beans that we have defined. The first one is the WebMessages. Of course both of these beans are samples and contain minimal fields.
package com.suvcodes.demo.cachebeans;
import java.io.Serializable;
import org.infinispan.api.annotations.indexing.Indexed;
import org.infinispan.api.annotations.indexing.Keyword;
import org.infinispan.protostream.annotations.ProtoField;
import org.infinispan.protostream.annotations.ProtoName;
@ProtoName("WebMessages")
@Indexed
public class WebMessages implements Serializable {
private static final long serialVersionUID = 1L;
@ProtoField(value = 1)
@Keyword
String messageId;
@ProtoField(value = 2)
@Keyword
String messageKey;
@ProtoField(value = 3)
String messageText;
public WebMessages() {
}
// Getters and Setters
}The second one is the Users bean.
package com.suvcodes.demo.cachebeans;
import java.io.Serializable;
import java.util.HashSet;
import java.util.Set;
import org.infinispan.api.annotations.indexing.Indexed;
import org.infinispan.api.annotations.indexing.Keyword;
import org.infinispan.protostream.annotations.ProtoField;
import org.infinispan.protostream.annotations.ProtoName;
@ProtoName("Users")
@Indexed
public class Users implements Serializable {
private static final long serialVersionUID = 1L;
@ProtoField(value = 1)
@Keyword
String userId;
@ProtoField(value = 2)
@Keyword
String email;
@ProtoField(value = 3)
Set<String> roles = new HashSet<>();
@ProtoField(value = 4)
String firstName;
@ProtoField(value = 5)
String lastName;
public Users() {
}
/* Getters and Setters */
}These files have quite a few differences from a regular Java bean. These are used to autogenerate the .proto files. The first thing of interest is @ProtoName. It field creates message type. @Indexed tells Infinispan to have this bean searchable. The next one is @ProtoField. Every field has to have an unique value. Rest of the @ fields provide instructions for Infinispan. One of the example is @Keyword.
Let’s now look at the configuration. We will have to define couple of interfaces that eventually creates corresponding classes. Each of these interfaces define the bean that it should create. Other than that, the path where generated file is saved is given. Finally we will have the configuration bean.
package com.suvcodes.demo.config.schemas;
import org.infinispan.protostream.GeneratedSchema;
import org.infinispan.protostream.annotations.ProtoSchema;
@ProtoSchema(
includeClasses = {
com.suvcodes.demo.cachebeans.WebMessages.class
},
schemaFileName = "webmessage.proto",
schemaFilePath = "proto/",
schemaPackageName = "webmessages"
)
public interface WebMessagesSchema extends GeneratedSchema {
}The other configuration interface looks similar.
package com.suvcodes.demo.config.schemas;
import org.infinispan.protostream.GeneratedSchema;
import org.infinispan.protostream.annotations.ProtoSchema;
@ProtoSchema(
includeClasses = {
com.suvcodes.demo.cachebeans.Users.class
},
schemaFileName = "users.proto",
schemaFilePath = "proto/",
schemaPackageName = "users"
)
public interface UsersSchema extends GeneratedSchema {
}Now that the interfaces are out of the way, let’s define the bean.
package com.suvcodes.demo.config;
import org.infinispan.client.hotrod.RemoteCacheManager;
import org.infinispan.client.hotrod.configuration.ClientIntelligence;
import org.infinispan.commons.marshall.ProtoStreamMarshaller;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.Ordered;
import org.springframework.core.annotation.Order;
import com.suvcodes.demo.config.schemas.UsersSchemaImpl;
import com.suvcodes.demo.config.schemas.WebMessagesSchemaImpl;
@Configuration
@EnableCaching
public class AppConfig {
@Value("${infinispan.remote.server-list}") private String serverList;
@Value("${infinispan.remote.auth-username}") private String username;
@Value("${infinispan.remote.auth-password}") private String password;
@Value("${infinispan.remote.client-intelligence}") private String clientIntelligence;
@Bean
@Order(Ordered.HIGHEST_PRECEDENCE)
public RemoteCacheManager createRemoteCacheManager() {
return new RemoteCacheManager(
new org.infinispan.client.hotrod.configuration.ConfigurationBuilder()
.addServer()
.host(serverList.split(":")[0])
.port(Integer.parseInt(serverList.split(":")[1]))
.security()
.authentication()
.username(username)
.password(password)
.clientIntelligence(ClientIntelligence.valueOf(clientIntelligence))
.marshaller(ProtoStreamMarshaller.class)
.addContextInitializer(new WebMessagesSchemaImpl())
.addContextInitializer(new UsersSchemaImpl())
.build()
);
}
}This will create the bean for remote client. If we do not use spring, same code can be used as well.
Now that we have the beans created, let’s look at the code for caching.
What we intend to build
As stated earlier, we will develop the process using two different methods. We will use manual query without using tools, and the second one will use Infinispan features. Let’s start with the first one.
In this case we want to store WebMessages and Users. WebMessages we will query using the messageId. On the other hand, for Users we will query using userId or email. Since Key/ Value for both classes is saved in same cache, we will have to use some other methodology to separate them.
To manually handle this scenario, we have two options. The first one is creating a single Java class and keeping both as List within it. However, that does not give us the benefit of search by keys. Instead we will use convention over configuration technique. We will store data using the following conventions.
- WebMessages will be stored as M-<messageId>. When needed, we can search by appending M in front of the messageId.
- For Users we will have U-<userId> as the key.
- Since we also need search by Email, we will create one more cache entry for each user with E-<email> as key and the <userId> as the value. If we need to search by Email, we go to this first, get the User ID and then search for the User.
Using these three we should be able to satisfy all requirements.
Conventional way
Let’s see how the REST controller looks like. We will have all the Cache saves also in here. These can be reused in later searches.
package com.suvcodes.demo.controllers;
import java.util.ArrayList;
import java.util.List;
import org.infinispan.client.hotrod.RemoteCache;
import org.infinispan.client.hotrod.RemoteCacheManager;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.DeleteMapping;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PutMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.suvcodes.demo.cachebeans.Users;
import com.suvcodes.demo.cachebeans.WebMessages;
@RestController
@RequestMapping("cache")
public class ManualCacheController {
@Value("${cacheName}")
private String cacheName;
/* Autowired */
private final RemoteCacheManager cacheManager;
public ManualCacheController(final RemoteCacheManager cacheManager) {
this.cacheManager = cacheManager;
}
/**
*
* User Starts here. Here we will demonstrate how to manage user indexing
* manually. We should be able to get users using Email or UserID.
*
* Here we will follow convention over configuration approach. We will assume
* that UserID and Email fields are unique. ID for Users will be prefixed with
* U- and Message Cache will be prefixed with M-.
*
* We will manage a redundant cache entry for each email that maps to the UserID.
* So when we need to get user by email, we will first get the UserID from the
* email cache and then get the user from the main user cache.
*
*/
@DeleteMapping("/clear")
public String clearCache() {
cacheManager.getCache(cacheName).clear();
return "Cache Cleared";
}
@PutMapping("/adduser")
public String addUser(@RequestBody Users entity) {
final RemoteCache<String, Users> userCache = cacheManager.getCache(cacheName);
final RemoteCache<String, String> emailCache = cacheManager.getCache(cacheName);
// See if Email exists
final String idFromEmail = emailCache.get("E-" + entity.getEmail());
if (idFromEmail != null) {
if (entity.getUserId().equals(idFromEmail)) {
userCache.put("U-" + entity.getUserId(), entity);
return "User Updated";
} else {
return "Email already exists for another user.";
}
} else {
userCache.put("U-" + entity.getUserId(), entity);
emailCache.put("E-" + entity.getEmail(), entity.getUserId());
return "User Added.";
}
}
@GetMapping("/getuserbyid")
public Users getUserById(String userId) {
final RemoteCache<String, Users> userCache = cacheManager.getCache(cacheName);
return userCache.get("U-" + userId);
}
@GetMapping("/getuserbyemail")
public Users getUserByEmail(String email) {
final RemoteCache<String, Users> userCache = cacheManager.getCache(cacheName);
final RemoteCache<String, String> emailCache = cacheManager.getCache(cacheName);
final String userId = emailCache.get("E-" + email);
if (userId != null) {
return userCache.get("U-" + userId);
} else {
return null;
}
}
@GetMapping("/getallusers")
public List<Users> getAllUsers() {
final List<Users> users = new ArrayList<>();
final RemoteCache<String, Object> cache = cacheManager.getCache(cacheName);
for (String key : cache.keySet()) {
if (key.startsWith("U-")) {
users.add((Users) cache.get(key));
}
}
return users;
}
@DeleteMapping("/deleteuser")
public String deleteUser(String userId) {
final RemoteCache<String, Users> userCache = cacheManager.getCache(cacheName);
final Users user = userCache.get("U-" + userId);
if (user != null) {
final RemoteCache<String, String> emailCache = cacheManager.getCache(cacheName);
emailCache.remove("E-" + user.getEmail());
userCache.remove("U-" + userId);
return "User Deleted";
} else {
return "User Not Found";
}
}
/**
* Message Starts here
*/
@PutMapping("/addmessage")
public String addMessage(@RequestBody WebMessages entity) {
final RemoteCache<String, WebMessages> messageCache = cacheManager.getCache(cacheName);
String messageId = "M-" + entity.getMessageId();
messageCache.put(messageId, entity);
return "Message Added with ID: " + messageId;
}
@GetMapping("/getmessagebyid")
public WebMessages getMessageById(String messageId) {
final RemoteCache<String, WebMessages> messageCache = cacheManager.getCache(cacheName);
return messageCache.get("M-" + messageId);
}
@GetMapping("/getallmessages")
public List<WebMessages> getAllMessages() {
final List<WebMessages> messages = new ArrayList<>();
final RemoteCache<String, Object> cache = cacheManager.getCache(cacheName);
for (String key : cache.keySet()) {
if (key.startsWith("M-")) {
messages.add((WebMessages) cache.get(key));
}
}
return messages;
}
@DeleteMapping("/deletemessage")
public String deleteMessage(String messageId) {
final RemoteCache<String, WebMessages> messageCache = cacheManager.getCache(cacheName);
messageCache.remove("M-" + messageId);
return "Message Deleted";
}
}In Line #28, we inject the bean using construction injection. Line #53 and Line #121 are REST Put methods to create new Users and WebMessage caches. If you see line #68, user is created with U- as key. We also create the next one as E- for email. Similarly, on line #124, messages will be added as M- key.
Rest of the code is for getters. Starting on line #81 we are searching by Email. We get the user ID associated with this Email. Next we search using the fetched User ID.
The Infinispan Way
Let’s now see how we can use Infinispan to query using ickle queries. We will not work on WebMessages. Let’s just see the class for Users.
If you remember, we had Email also as Keyword. This means, Infinispan has indexed it for us. I will also add one more criteria to get all users by Role.
package com.suvcodes.demo.controllers;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.security.SecureRandom;
import java.util.List;
import org.infinispan.client.hotrod.RemoteCache;
import org.infinispan.client.hotrod.RemoteCacheManager;
import org.infinispan.client.hotrod.RemoteSchemasAdmin.SchemaOpResult;
import org.infinispan.client.hotrod.impl.query.RemoteQueryFactory;
import org.infinispan.commons.api.BasicCache;
import org.infinispan.commons.api.query.Query;
import org.infinispan.protostream.schema.Schema;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.PutMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.suvcodes.demo.cachebeans.Users;
@RestController
@RequestMapping("users")
public class UserGetController {
@Value("${cacheName}")
private String cacheName;
final SecureRandom rand = new SecureRandom();
final String[] randomRole = {"admin", "developer", "monitor", "operator", "auditor"};
final String[] randomFirstName = {"John", "Jane", "Alice", "Bob", "Charlie", "Diana", "Eve", "Frank", "Grace", "Hank"};
final String[] randomLastName = {"Smith", "Johnson", "Williams", "Brown", "Jones", "Garcia", "Miller", "Davis", "Rodriguez", "Martinez"};
final static Logger log = LoggerFactory.getLogger(UserGetController.class);
/* Autowired */
private final RemoteCacheManager cacheManager;
public UserGetController(final RemoteCacheManager cacheManager) {
this.cacheManager = cacheManager;
}
@PostMapping("/register")
public String registerSchema() throws Exception {
final Path proto = Paths.get(UserGetController.class.getClassLoader()
.getResource("proto/users.proto").toURI());
final SchemaOpResult result = cacheManager
.administration()
.schemas()
.createOrUpdate(Schema.buildFromStringContent("users.proto", Files.readString(proto)));
if (result.hasError()) {
log.error("Schema registration failed: {}", result.getError());
return "Schema registration failed: " + result.getError();
} else {
log.info("Schema registered successfully.");
return "Schema registered successfully.";
}
}
// This is the other way of registering the schema.
// It uses protobug metadata schema to save it.
@PostMapping("/register2")
public String registerSchemaV2() throws Exception {
final Path proto = Paths.get(UserGetController.class.getClassLoader()
.getResource("proto/users.proto").toURI());
// Now get the protobuf metadata and store this content
final RemoteCache<String, String> metadataCache = cacheManager.getCache("___protobuf_metadata");
metadataCache.put("users.proto", Files.readString(proto));
log.info("Schema registered successfully.");
return "Schema registered successfully.";
}
@GetMapping("/getbyid/{id}")
public List<Users> getUserById(@PathVariable("id") String id) {
log.info("Fetching user with ID: {}", id);
final Query<Users> query = cacheManager.getCache(cacheName)
.query("FROM users.Users WHERE userId = :idParam");
query.setParameter("idParam", id);
final List<Users> user = query.execute().list();
return user;
}
@GetMapping("/getbyemail/{email}")
public List<Users> getUserByEmail(@PathVariable("email") String email) {
log.info("Fetching user with ID: {}", email);
final Query<Users> query = cacheManager.getCache(cacheName)
.query("FROM users.Users WHERE email = :idParam");
query.setParameter("idParam", email);
final List<Users> user = query.execute().list();
return user;
}
@GetMapping("/getbyrole/{role}")
public List<Users> getUserByRole(@PathVariable("role") String role) {
log.info("Fetching user with ID: {}", role);
final Query<Users> query = cacheManager.getCache(cacheName)
.query("FROM users.Users WHERE roles = :idParam");
query.setParameter("idParam", role);
final List<Users> user = query.execute().list();
return user;
}
}One quick note here, because we are working on custom datatypes, we will have to register these objects on the server. This is normally done as soon as we start the application, however for this application, I have created a web method to register it. This starts on line #48. If you see the getter methods, you will notice we have SQL query type of queries with <package>.<name> as the object where we search. So, for users, we are using users.Users as the name. We can use any field names that are searchable in the query to search. In this case we are searching on userId, email and roles in the three getter methods. This makes ir easier for us to search without having to deal with an additional cache.
Conclusion
This blog turned out to be lot longer than I anticipated. However, I have tried to cover most of the questions that my team had so that it can also help others in the same boat. Hope you found this useful. Ciao for now!